LoRA: Low-Rank Adaptation of Large Language Models
In this post, we introduce the paper “LoRA: Low-Rank Adaptation of Large Language Models” by Edward Hu, Yelong Shen, Phillip Wallis, Zeyu Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. The paper was published at ICLR 2022.
The era of LLMs
Large language models have become ubiquitous, with their development and deployment having transformed the field of artificial intelligence in recent years. These models, such as GPT-4, have been trained on massive amounts of data and are capable of understanding and generating human-like language with a high degree of accuracy. They have been used in a variety of applications, from language translation to chatbots and voice assistants.
Fine-tuning LLMs efficiently
However, since they are large, they require a lot of resources to train, which cannot be done by individuals. Therefore, one may fine-tune the models for their specific purpose or add adapters to make them work well on downstream tasks while keeping the additional training efficient. There are some issues with existing methods, but with limitations.
Introduce inference latency by extending model depth
[Houlsby et al.] and [Lin et al.] add some adaptive layers (two adapter layers per Transformer block or one per block + additional LayerNorm), which obviously introduces additional computations. Some of the later works ([Rücklé et al.] and [Pfeiffer et al.]) reduces the overall latency by applying pruning, but this can’t bypass the extra computation from adaptive layers. Although they add only small number of parameters (less than 1% compared to the original model), adding such adaptation layers can introduces bottlenecks for hardware parallelization. The below table (Table 1) shows the increase in latency when using the above adapters, which is more than 20% to 30% in some cases. Note that the problem worsens when we need to shard the model because the additional depth requires more synchronous GPU operations, unless we store the adapter parameters redundantly multiple times.

Reduce the model’s usuable sequence length
[Li and Liang] proposed prefix-tuning, inspired by prompt-tuning of LLMs. Instead of appending task-specific natural langauge at the beginning (e.g. TL;DR for summarizing tasks), prefix-tuning append continuous task-specific vectors, which they call prefix. This can be considered as appending virtual learnable tokens at the beginning, which may not correspond to any real tokens. This only adds a small number of parameters for such prefixes (<0.1% of total parameters). However, one needs to reserve a part of the sequence length for prefixes and necessarily reduces the sequence length available to process a downstream task. It has been observed that prefix-tuning is difficult to optimize and that its performance changes non-monotonically in trainable parameters.
Fail to match the fine-tuning baselines
At last, most of the previous works often fail to match the performances of the full fine-tuning baselines.
LoRA
Inspired by the work of [Aghajanyan et al.], the authors of LoRA hypothesize that the updates to the weights have a low “intrinsic rank” during adaptation. Based on the hypothesis, the idea of LoRA is very simple: we impose a restriction on the rank of the matrices for the parameter increment by writing it as $\Delta W = BA$, where $\Delta W \in \mathbb{R}^{d \times k}$ and $B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}$ for some $r$ which is chosen to be much smaller than $d$ and $k$. In other words, the rank of the increament is at most $r$. We freeze the initial parameters $W_0 \in \mathbb{R}^{d \times k}$ during training, and the modified forward pass (after training) would be
\[h = W_0 x + \Delta W x = W_0 x + BA x.\]The matrix $A$ is initialized along Gaussian distribution, and the matrix $B$ is initialized as a zero matrix. Figure 1 gives a description of LoRA, where the blue pre-trained weights are freezed and the orange matrices are new parameters to be trained. LoRA can be regarded as a generalization of full fine-tuning, as the full fine-tuning can be thought as updating parameters without any rank restrictions. Also, at the inference stage, it does not introduce any additional computations since the overall network architecture remains the same.
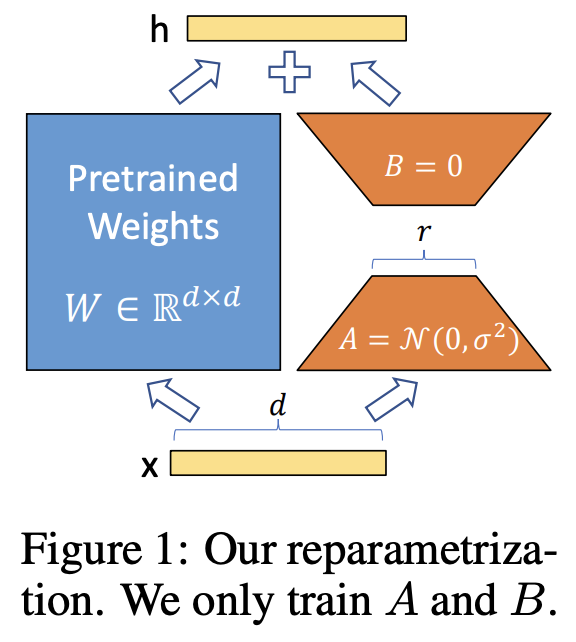
Applying LoRA to transformers
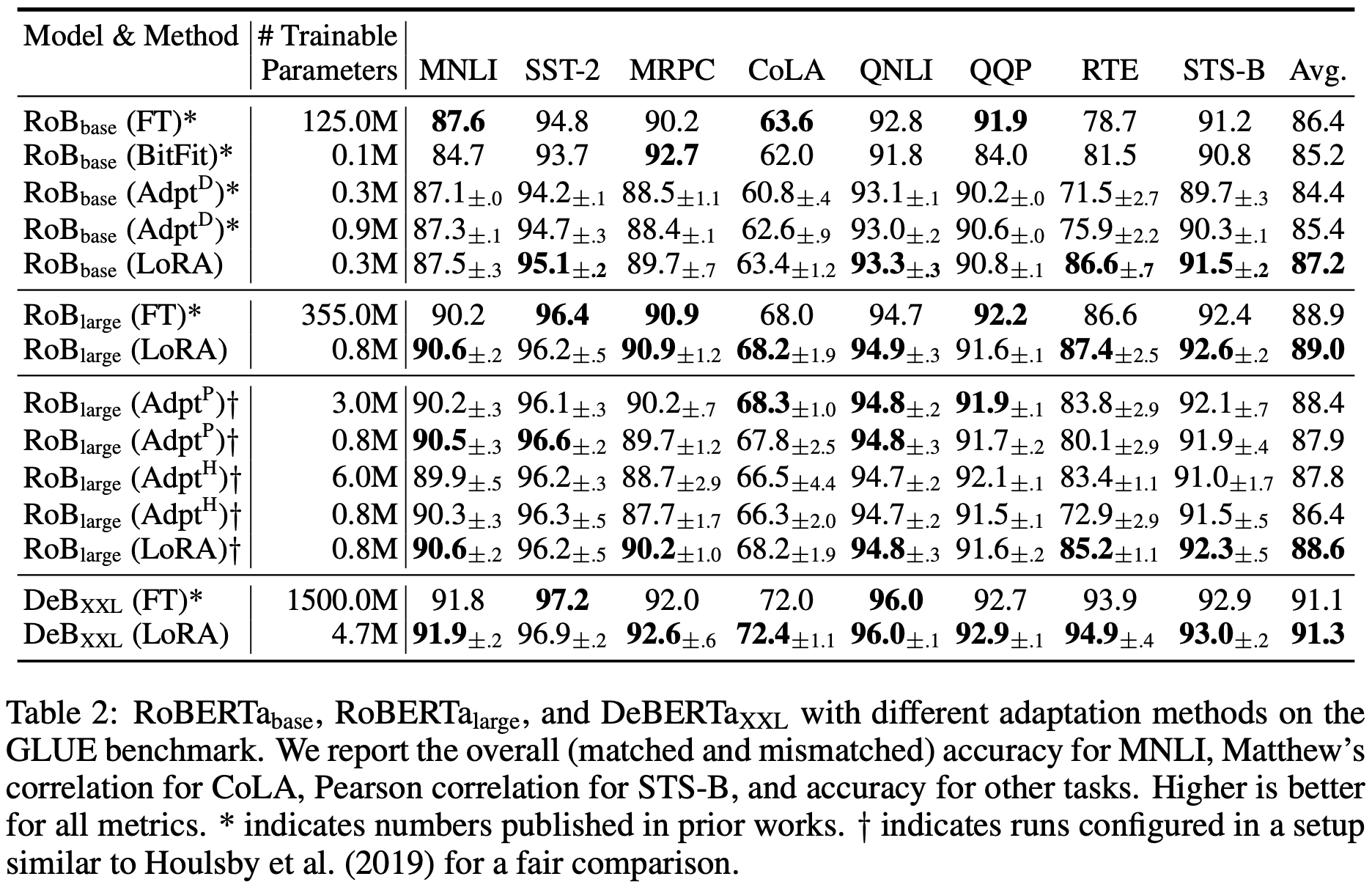
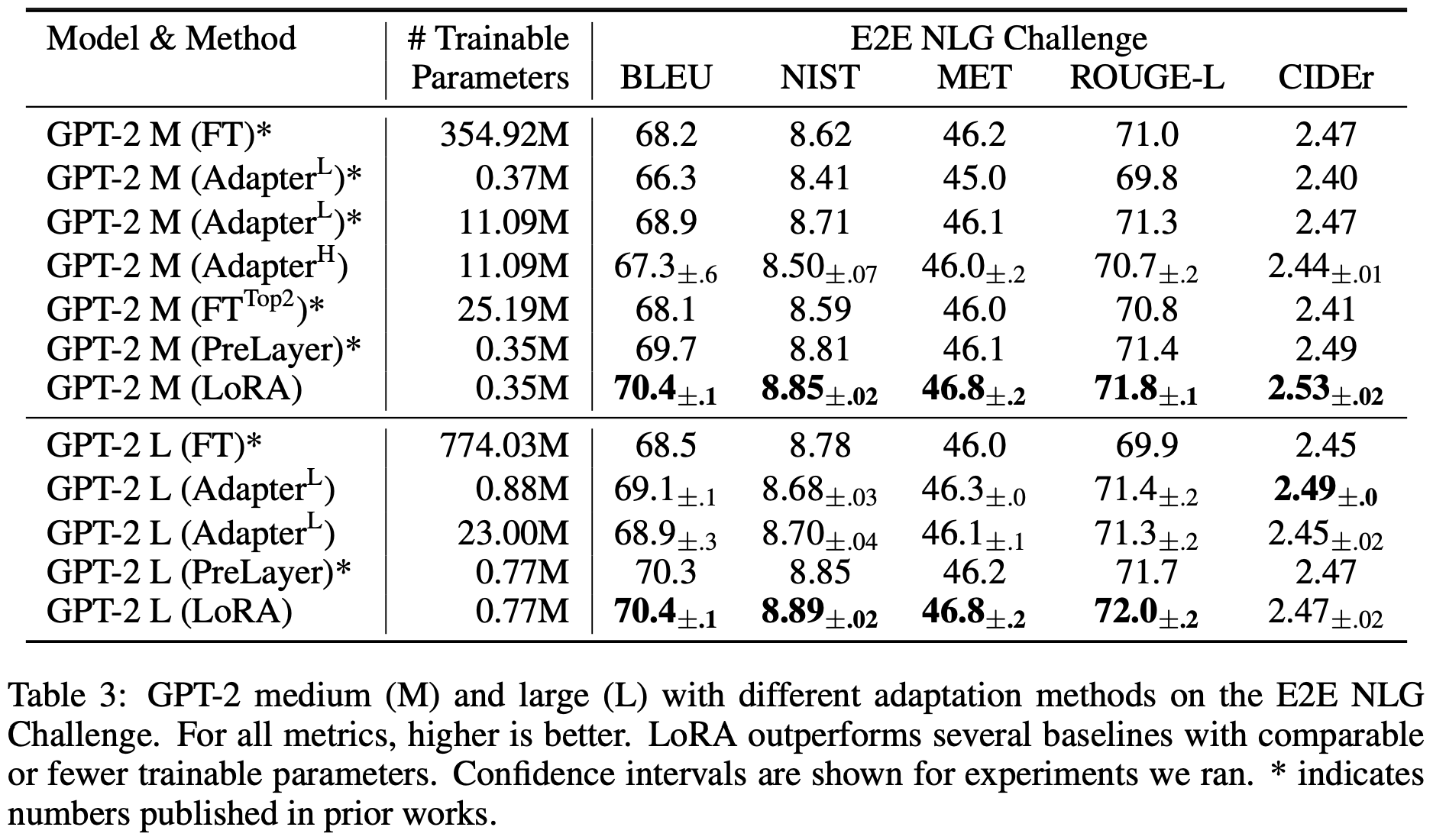
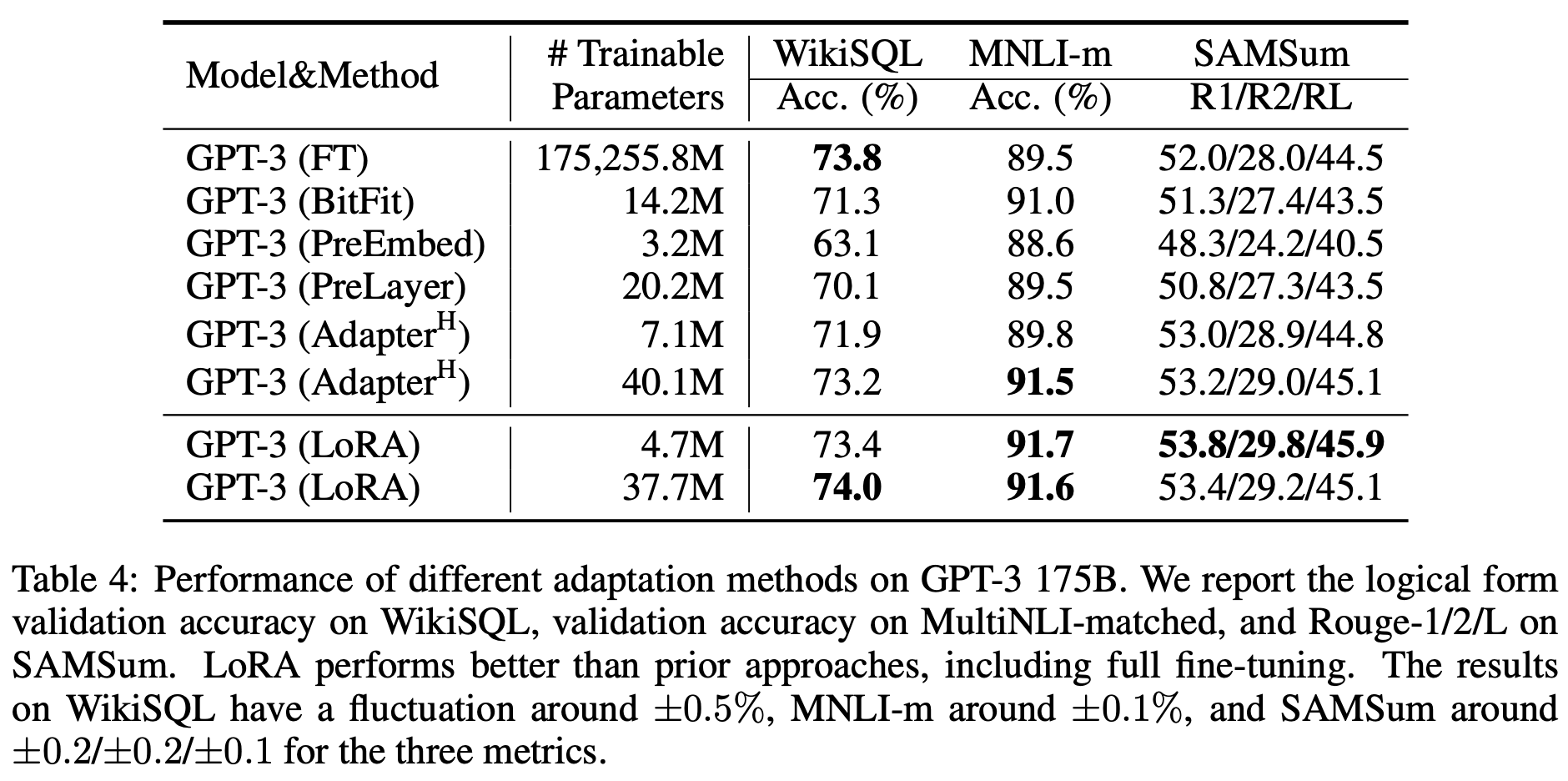
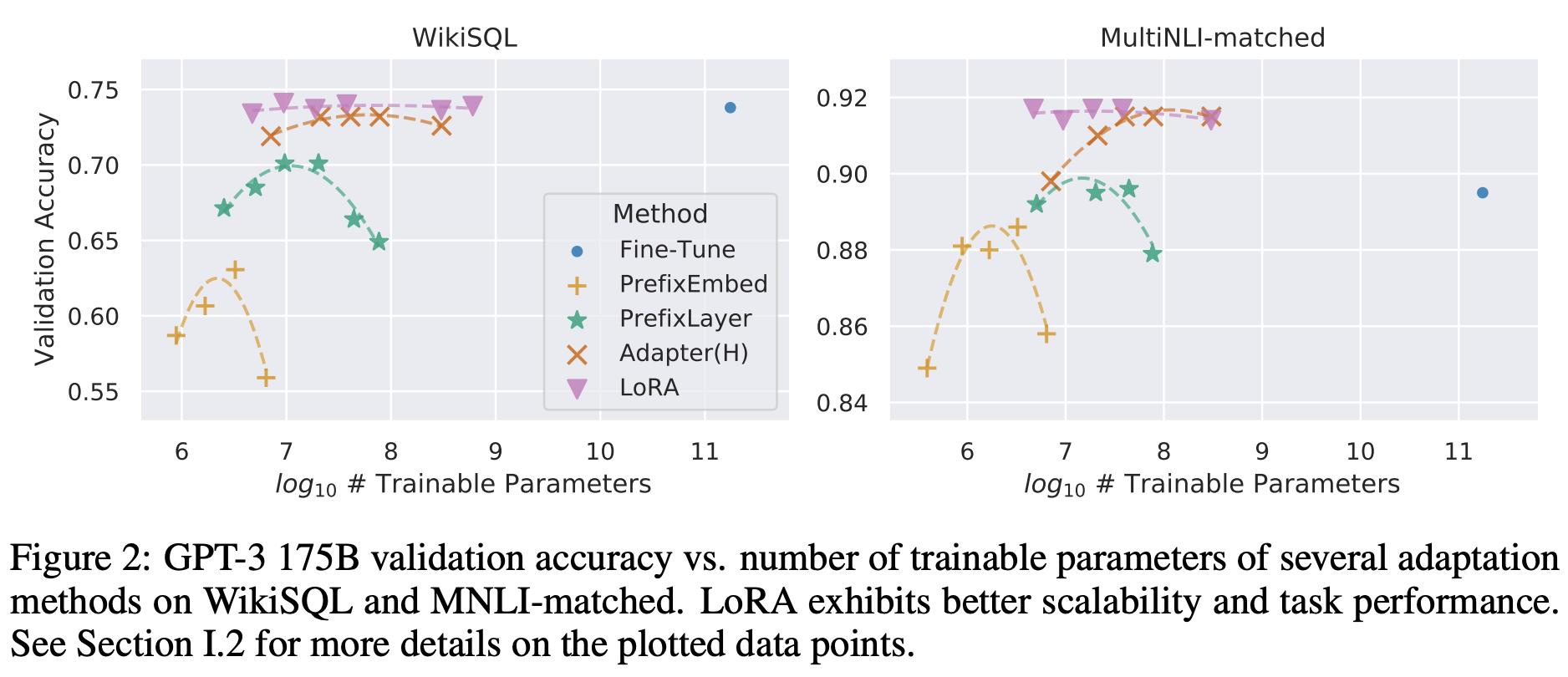
In theory, LoRA can be applied to any subset of matrices of any neural networks, but this paper concentrates on the transformer-based LLMs. Especially, there are four weight matrices in self-attension module (correspond to query, key, value, and output transforms) and two in the MLP (feed-forward) module, and the authors limit their strudy to only adapting the attention weights (and freeze MLP modules, LayerNorms, and biases). The following tables (Table 2, 3, 4) show the comparison results of LoRA with other baselines, including full fine-tuning (FT), bias-only (BitFit, [Zaken et al.]), prefix-embedding tuning (PreEmbed, [Li and Liang]), prefix-layer tuning (PreLayer), and adapter tunings (Adapter, [Houlsby et al.], [Lin et al.], [Pfeiffer et al.], [Rücklé et al.]), applied to RoBERTa, DeBERTa, GPT-2, and GPT-3.
Also, the following Figure 2 shows how the performance varies as we increase the number of trainable parameters for each methods.
Post works and conclusion
After the paper published in ICLR 2022, there are some post works that improves LoRA. For example, [Liu et al.] introduces $(\texttt{IA})^3$, which stands for “Infused Adapter by Inhibiting and Amplifying Inner Activations”. It adds small number of learnable vectors that rescales the model’s activations.
LoRA and other parameter efficient fine-tuning methods (e.g. Adapters) are already used in practice. For example, this Lit-LLAMA repository provides scripts for both fine-tuning methods which can be done very easily. As LLMs get bigger and bigger, the importance of efficient fine-tuning will increase too.
References:
[Aghajanyan et al.] Intrinsic Dimensiontality Explains the Effectiveness of Language Model Fine-Tuning, arXiv:2012.13255 (2020)
[Houlsby et al.] Parameter-Efficient Transfer Learning for NLP,arXiv:1902.00751 (2019)
[Li and Liang] Prefix-Tuning: Optimizing Continuous Prompts for Generation, arXiv:2101.00190 (2021)
[Lin et al.] Exploring versatile generative language model via parameter-efficient transfer learning, Finings of the Association for Computational Linguistics: EMNLP (2020)
[Liu et al.] Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Advances in Neural Information Processing Systems 35 (2022)
[Pfeiffer et al.] Adapter-fusion: Non-distructive task composition for transfer learning (2021)
[Rücklé et al.] Know that you don’t know: Unanswerable questions for squad, CoRR, abs/1806.03822 (2018)
[Zaken et al.] Bitfit: Simple parameter-efficient fine-tuning for transformer-based mask language-models (2021)
Tags:machine-learning